
# 第一章-分类
万丈高楼平地起
并行计算的分类从两个角度区分,同时介绍并行计算的编程模型。
# 费林分类法
Flynn's classic taxonomy,从指令和数据角度看待。用一幅图描述费林分类法:

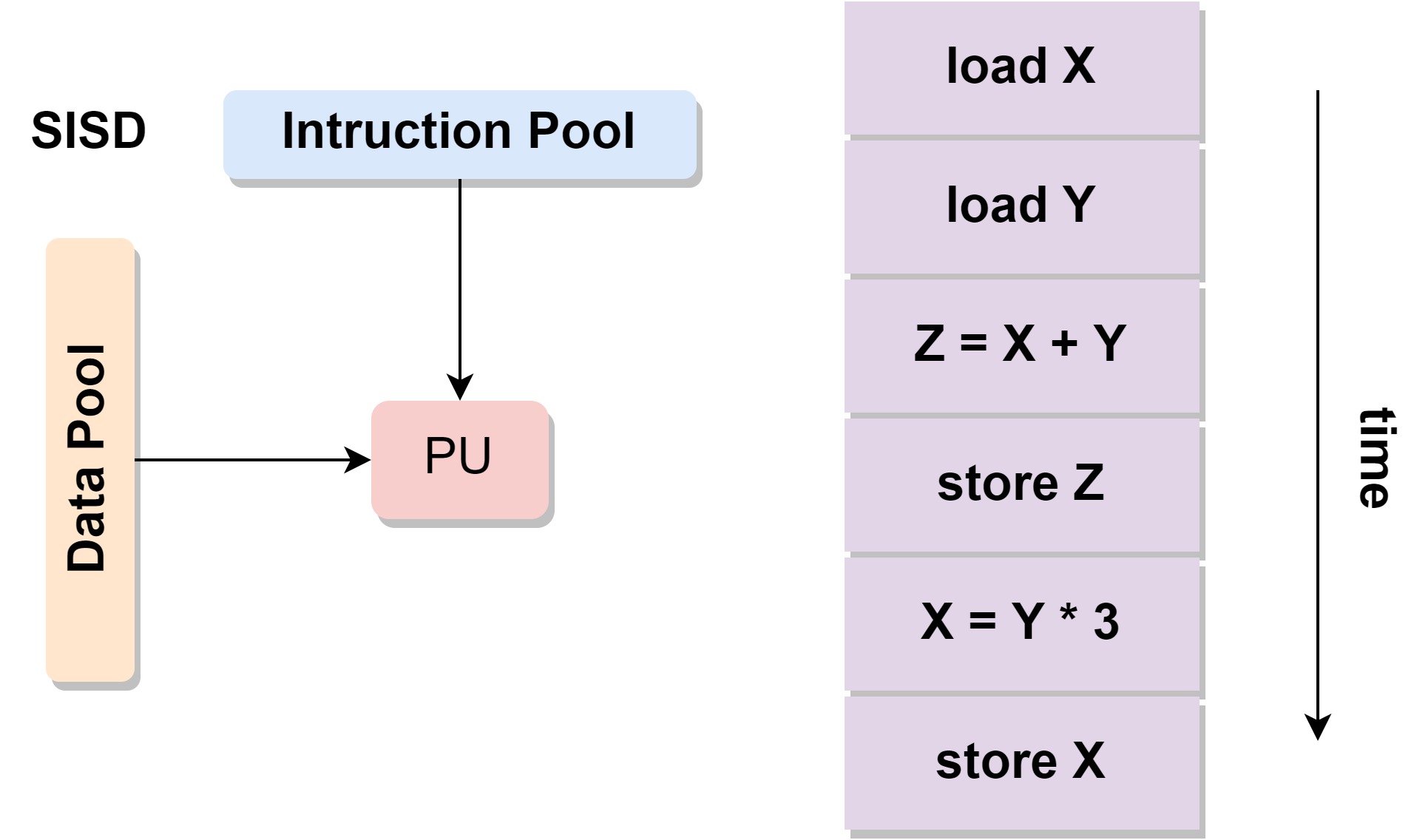
# SISD
Single Instruction, Single Data.单指令单数据流。
- 串行计算机
- 单指令:在处理器上一个时钟周期只有一个指令流被执行
- 单数据:在一个时钟周期只有一个数据流被使用
- 例子:single-core processor
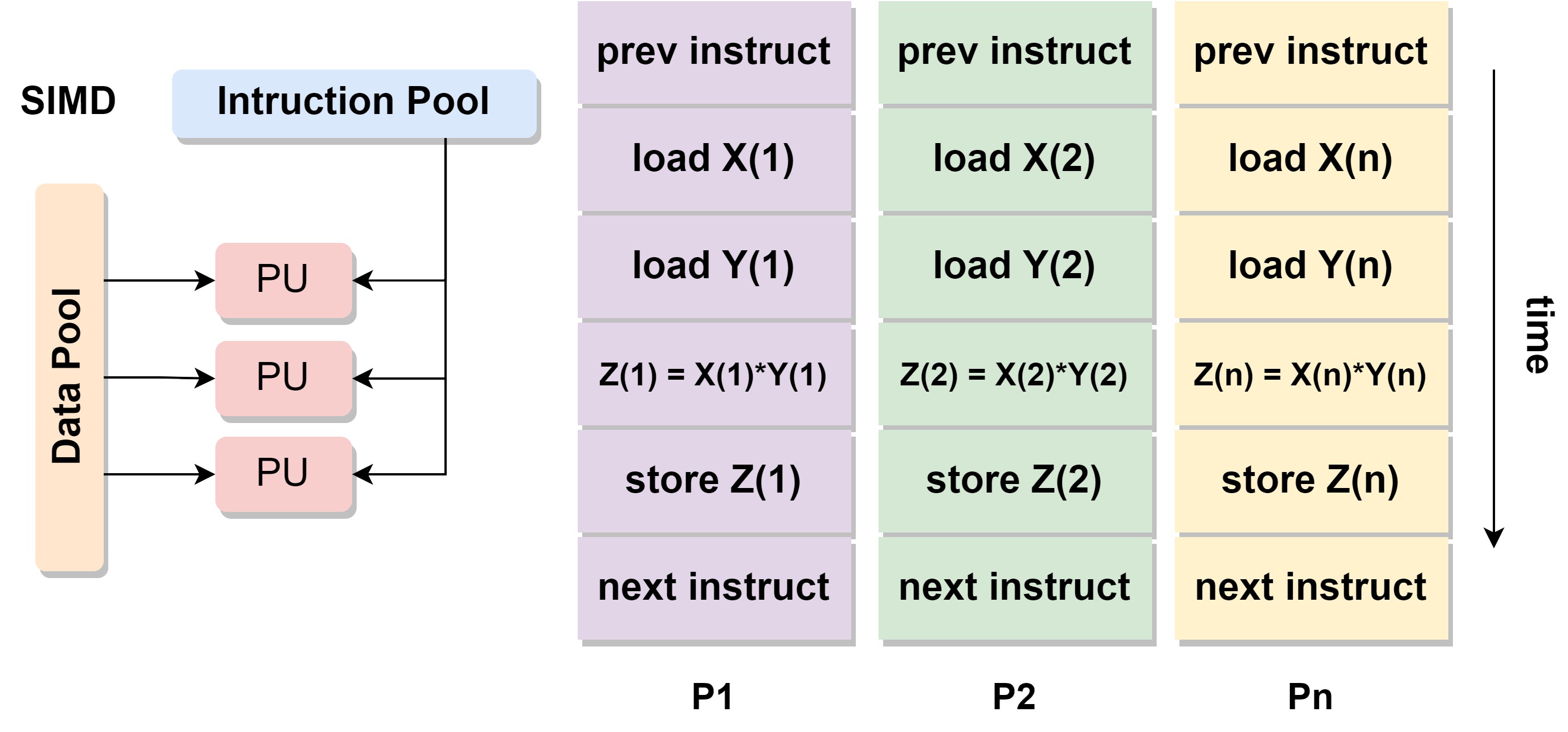
# SIMD
Single Instruction, Multiple Data.单指令多数据流。
- 单指令:所有的处理单元处理相同的指令
- 多数据:不同的处理单元处理不同的数据
- 例子:GPU,vector processor (X86 AVX instruction)
在cuda编程中是非常典型的应用。不同的thread使用相同的代码,通过不同的数据索引来处理不同位置的数据。
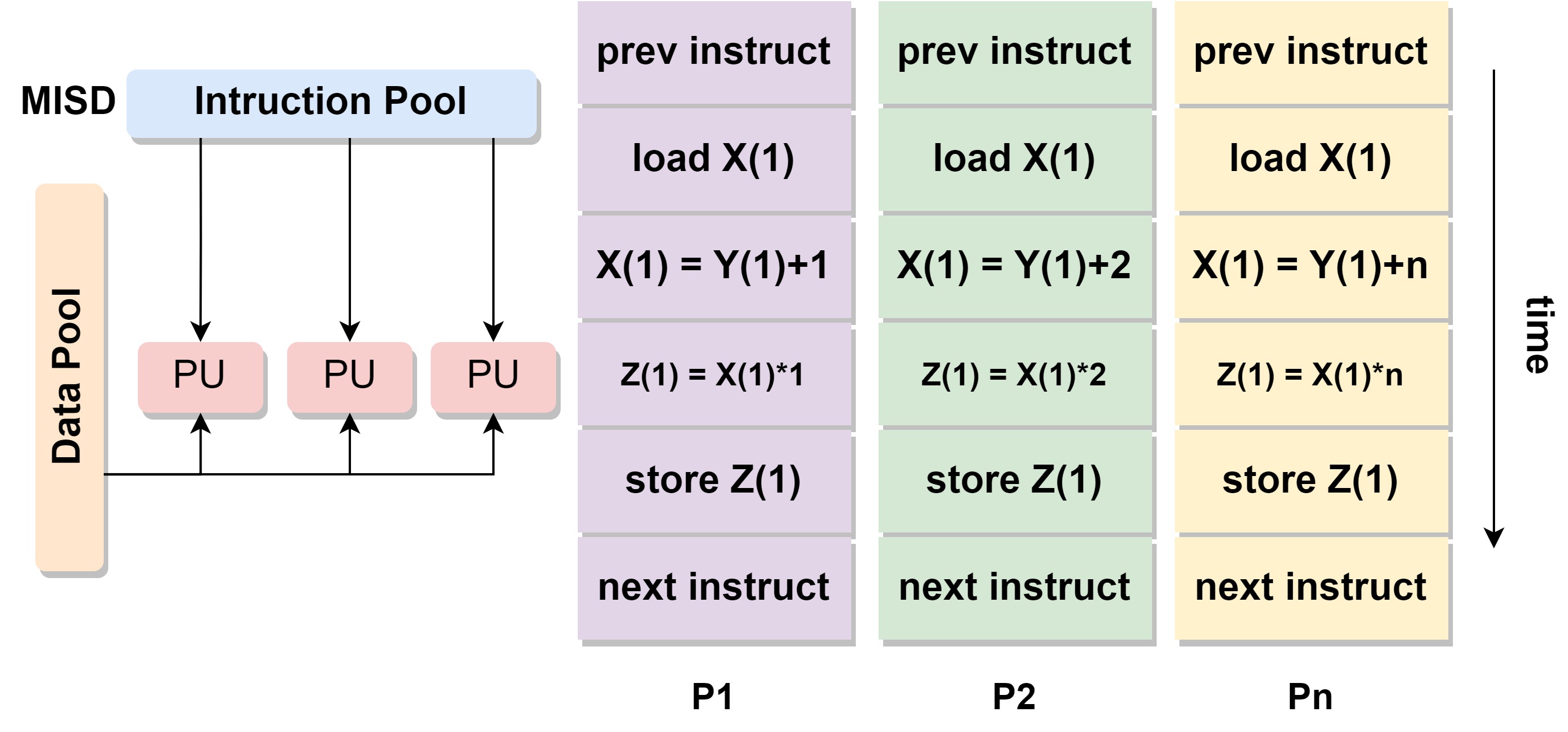
# MISD
Multiple Instruction, Single Data.多数据单指令流。
- 多指令:每个处理器执行不同的指令流
- 单数据:一个数据流被输入进不同的处理单元
- 例子:只有1971年CMU实现,能被用于 fault tolerance
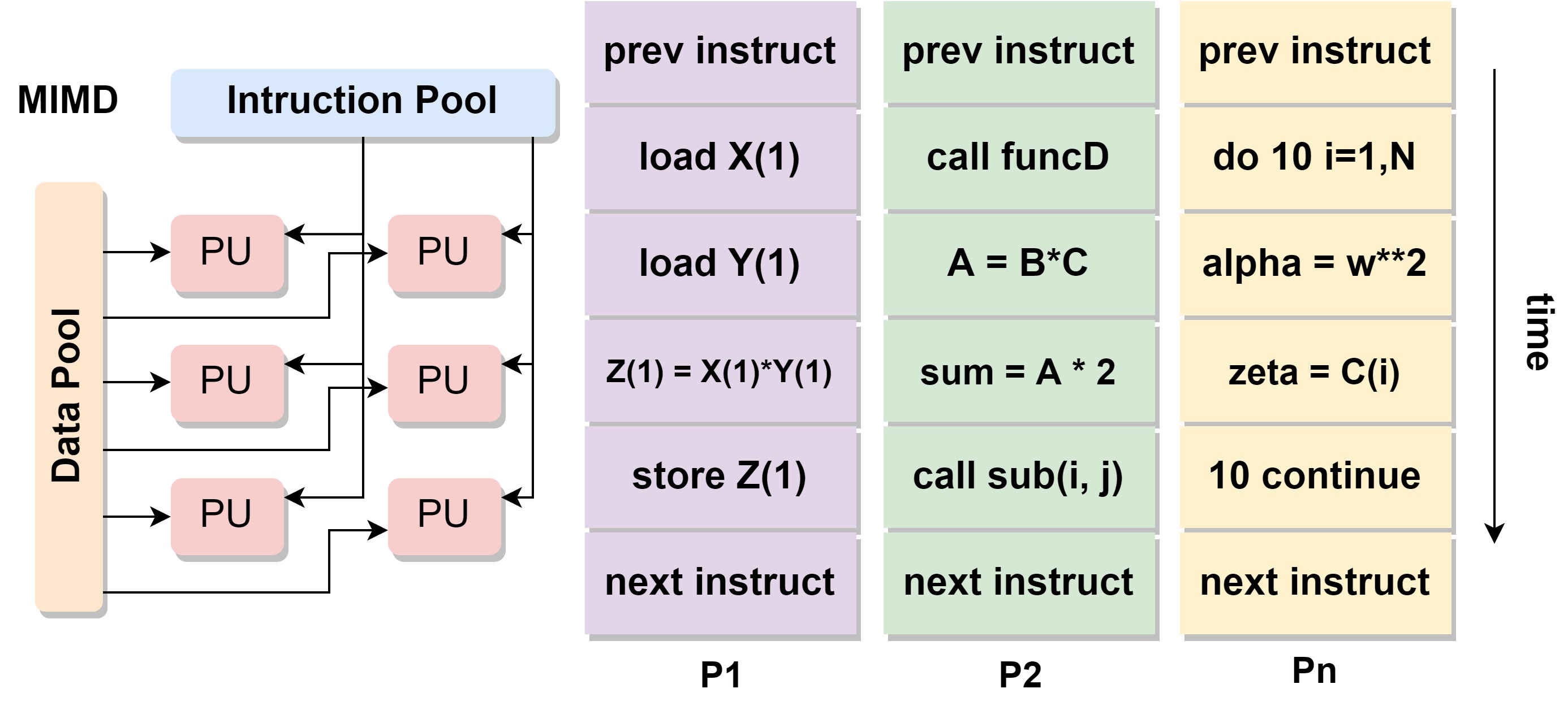
# MIMD
Multiple Instruction, Multiple Data.多指令多数据流。
- 多指令:每个处理器处理不同的指令流
- 多数据:每个处理器处理不同的数据流
- 例子:Most modern computers,如multi-core CPU
# 内存架构分类法
Memory architecture classification。从内存架构的角度来对并行计算分类。Shared Memory Computer Architecture、Distributed Memory Computer Architecture 和 Hybrid Distributed-Shared Memory。
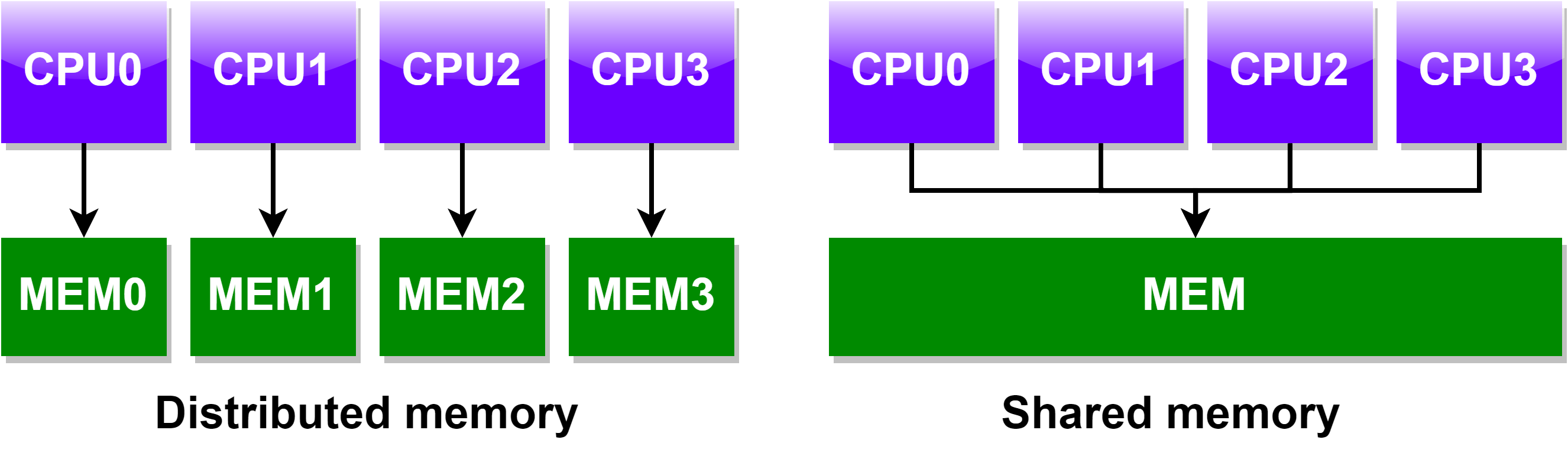
# Shared Memory Computer Architecture
共享内存的并行计算架构有分为:Non-Uniform Memory Access 和 Non-Uniform Memory Access。
# Uniform Memory Access (UMA)
- 在今天大多是对称多处理器系统 SMP (Symmetric Multiprocessor machines)
- 处理器相同
- 访存 memory 时间相同
- 例子:商业服务器
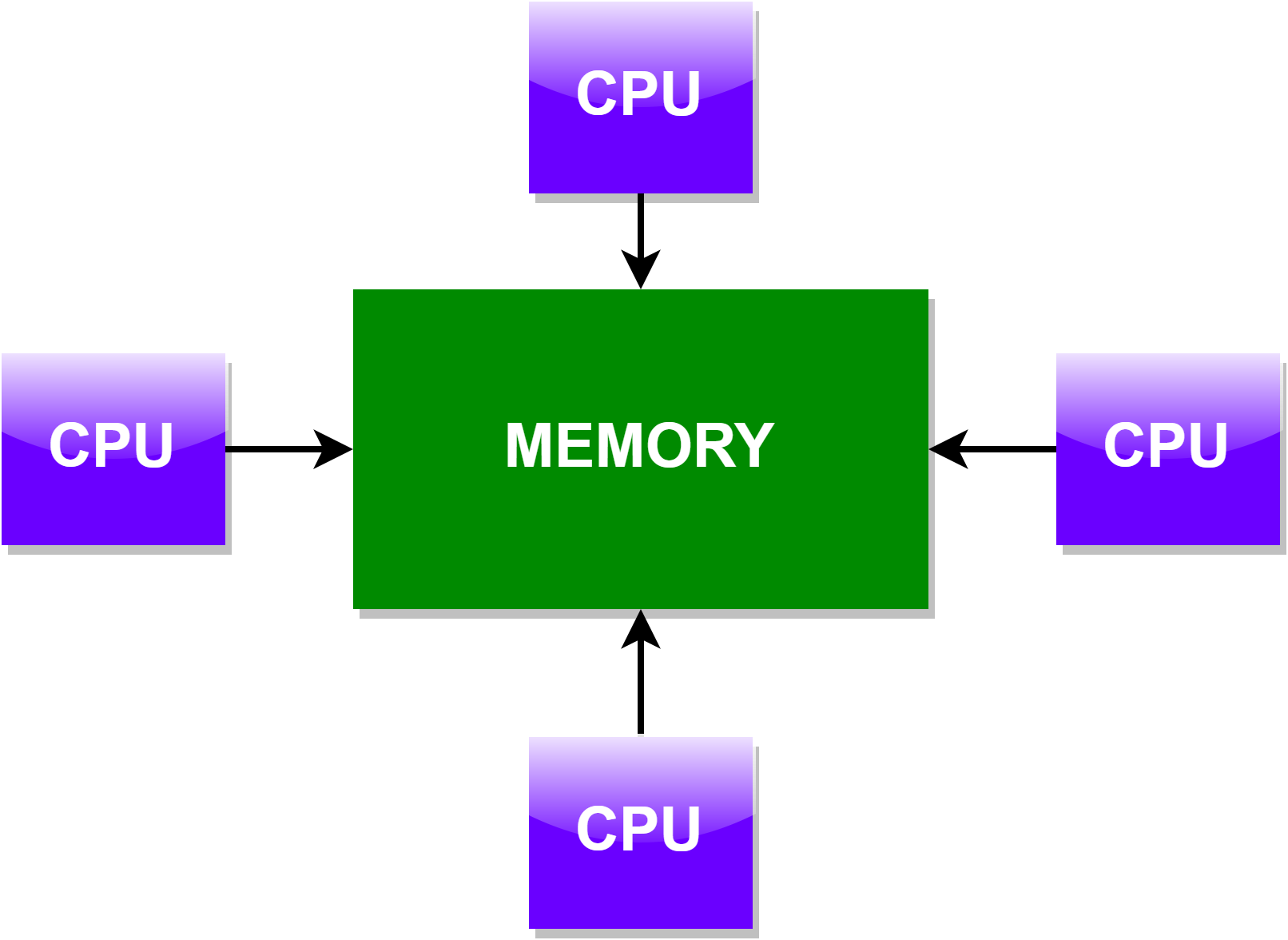
# Non-Uniform Memory Access (NUMA)
- 通常由至少两个SMP通过物理连接组成
- 一个 SMP 能够直接访存另一个 SMP 的 Memory
- 不同 SMP 之间通过连接访存 memory 的速度比较慢
- 例子:HPC Server

# Distributed Memory Computer Architecture
- 需要连接网络
- 处理器有自己的内存和地址空间
- 一个处理器内存的变化不影响其他处理器的内存
- 程序员或者编程工具需要显示的定义:how and when data is communicated between processors
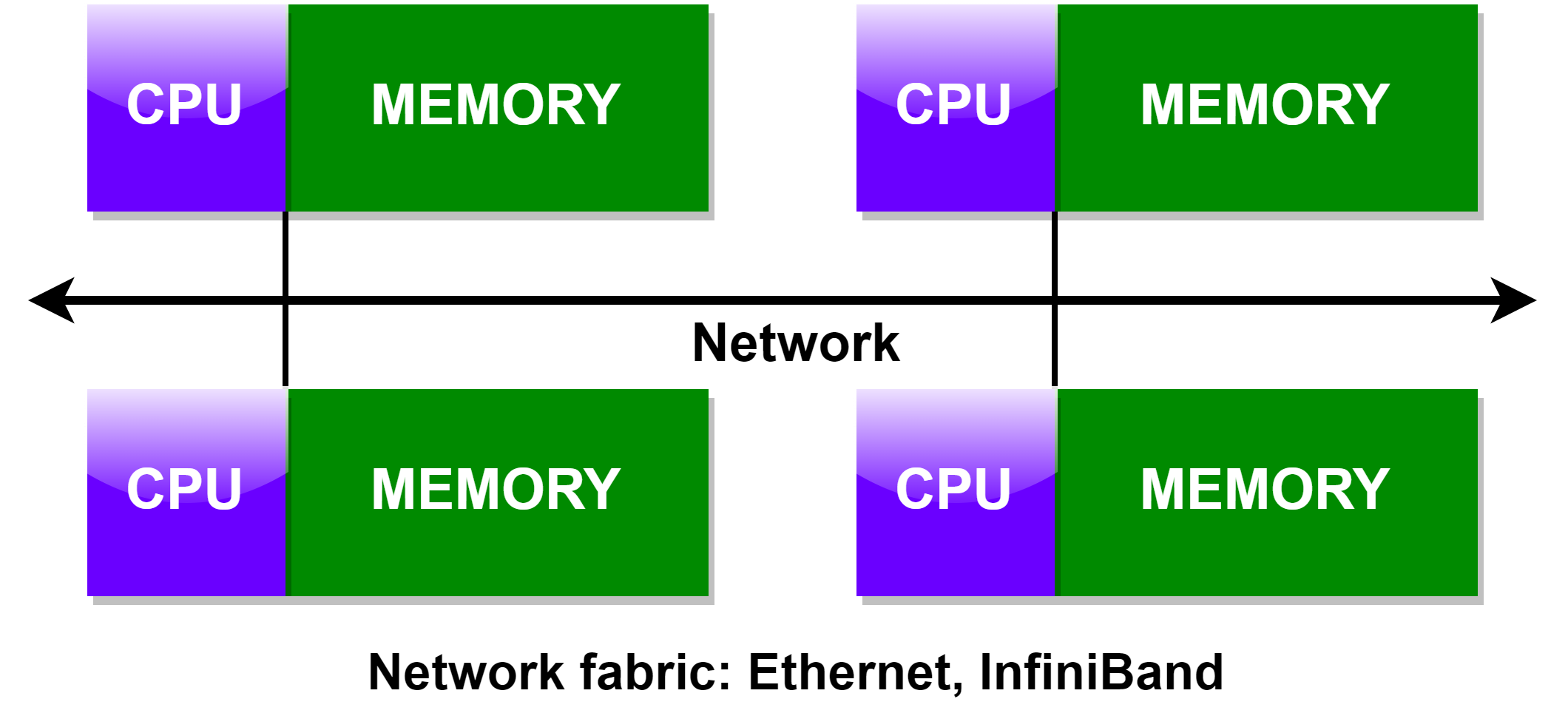
# Hybrid Distributed-Shared Memory
- 当今的计算机既有共享内存架构也有分布式内存架构
- 共享内存 component 可以是共享内存机器
- 分布式内存 component 由网络连接的多台共享内存机器组成
- 未来的并行计算架构会一直是混合模式

# 并行编程模型分类
Parallel Programming model classification。并行计算编程模型是在硬件和内存架构的基础之上抽象出来的结构,分类为:Shared Memory Programming Model、Message Passing Programming Model 和 Hybrid Programming Model。
通常的编程模型是为了匹配计算机的物理架构,
◇ 共享内存的编程模型匹配共享内存的计算机架构
◇ 消息传递的编程模型匹配分布式内存计算机架构
但是编程模型并不需要严格的受限于计算机架构,
◇ 消息传递编程模型可用在共享内存的计算机架构上。例:把 MPI 用到单台服务器上
◇ 共享内存编程模型可用在分布式内存计算机架构上。例:Partitioned Global Address Space
# Shared Memory Programming Model
- 一个处理器拥有多个、并发的处理路径
- Threads 有局部数据,但是同时有共享的资源
- Threads 之间通过 global memory 沟通
- Threads 能够创建和销毁,但是主程序要保留:提供必要的共享资源直到程序完成
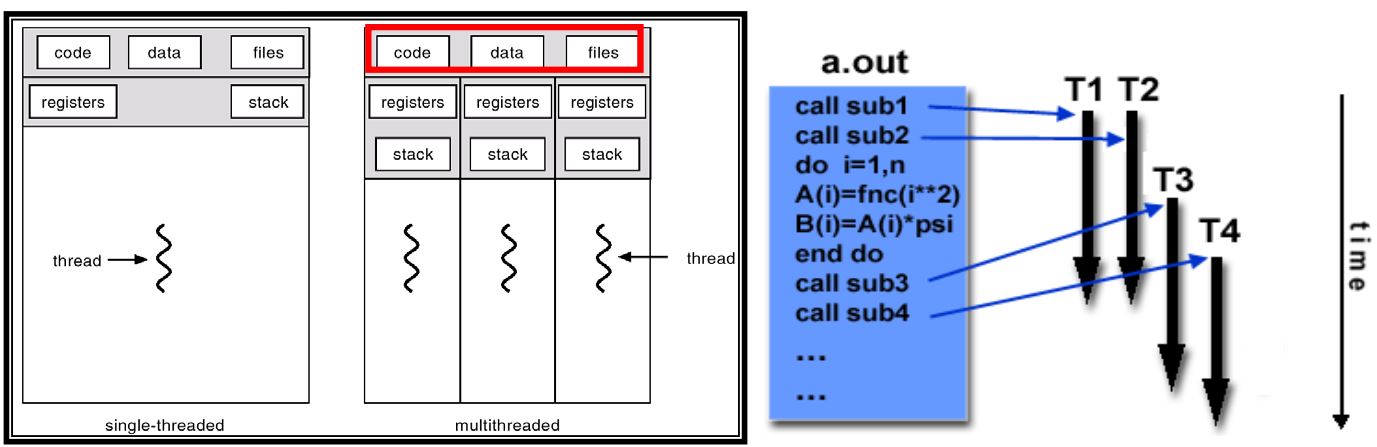
共享内存并行计算编程模型实现方法:
- A library of subroutines called from parallel source code, E.g.: POSIX Thread (Pthread)
- A set of compiler directives imbedded in either serial or parallel source code. E.g.: OpenMP
# Message Passing Programming Model
- 每个 task 在处理任务时使用自己的局部内存,多个 tasks 能够经过任意数量的物理机器访问同一个机器
- 多个 tasks 的数据交换通过:communications by sending and receiving messages
- 实现:MPI
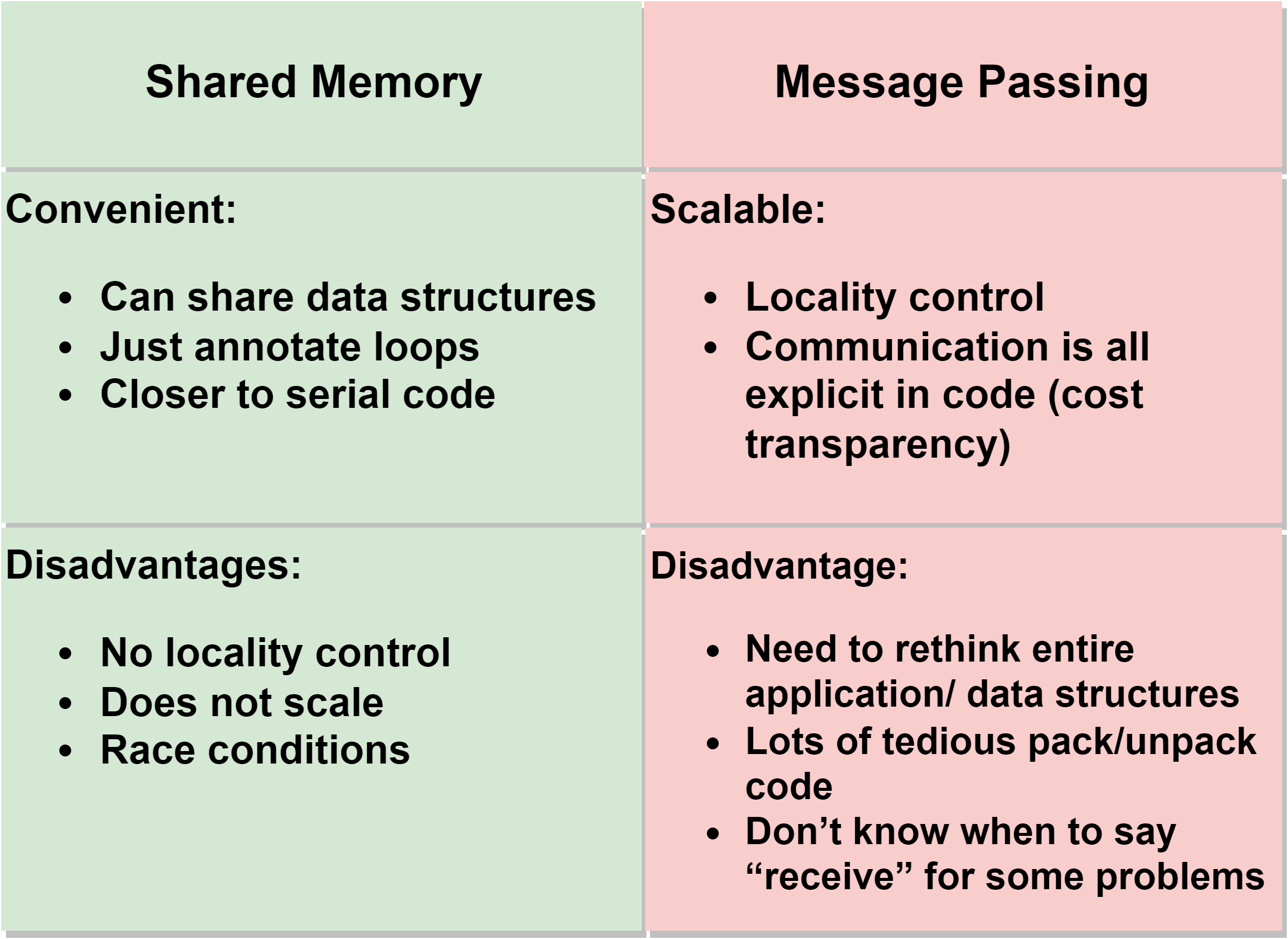
共享内存并行编程模型 和 消息传递并行编程模型 的对比:
# Hybrid Programming Model
由上述几种模型混合组成
混合模型适用于现有的硬件和软件架构
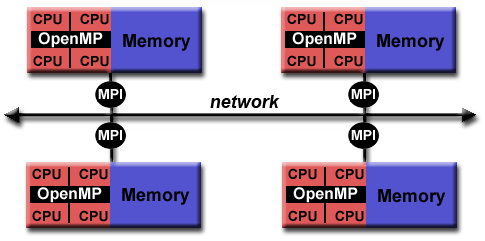
例子:message passing model (MPI) 和 threads model (OpenMP)的混合,如图:
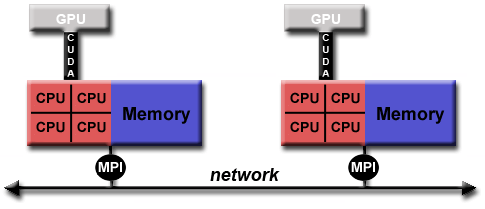
例子:message passing model (MPI) 和 CPU-GPU 混合
- MPI 程序跑在 CPUs 上,使用局部内存,通过网路进行通信
- 密集计算的程序跑在 GPUs 上
- 数据在单机内存和 GPU 之间的传输通过 CUDA 实现
# 总结
⭐️ 编程模型和并行系统架构的发展是相互影响的
⭐️ openMP, MPI, Pthreads, CUDA 只是做并行计算的编程语言
⭐️ 知道什么是并行计算比怎么做并行计算更加重要:
♦ 更快的学习新的并行编程工具
♦ 理解自己程序的性能
♦ 优化自己程序的性能
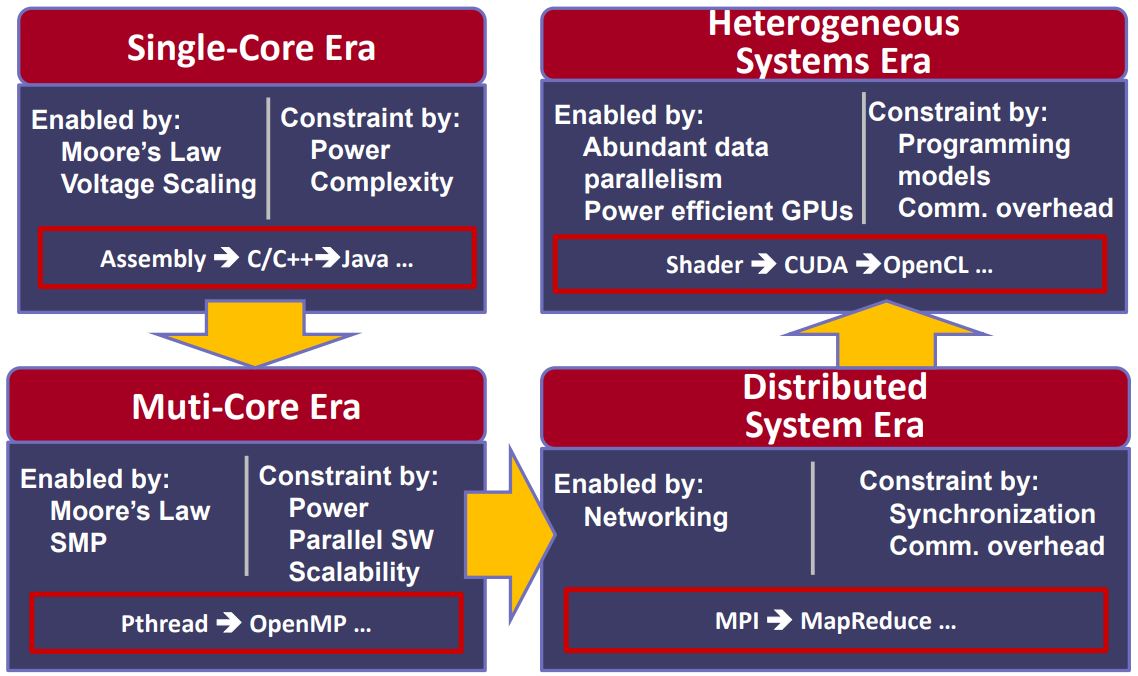
最后用一幅图来说明并行计算的发展趋势:
# 参考资料
Introduction parallel computing tutorial (opens new window)
台湾新竹清华大学 平行程式 (opens new window)